Noramlization (정규화)
normalization 은 데이터의 범위를 0~1 사이의 값으로 변환한다.
값의 범위가 다르면 직접 비교가 불가능 하기 때문에 학습에 앞서 데이터의 스케일을 맞춰주는 것이다. 예를 들면 1000점 만점인 시험에서의 100점과 100점 만점인 시험에서의 100점은 범위가 다르기 때문에 그대로 비교 할 수 없다. 정규화를 거치게 되면 0.1과 1이라는 값으로 변환되어 100점이라는 점수가 각 시험에서 어떤 중요도를 갖는지 알 수 있게 된다. 이처럼 모든 데이터가 동일한 정도의 스케일(중요도)로 반영되도록 해주는게 정규화의 사용 이유이다.
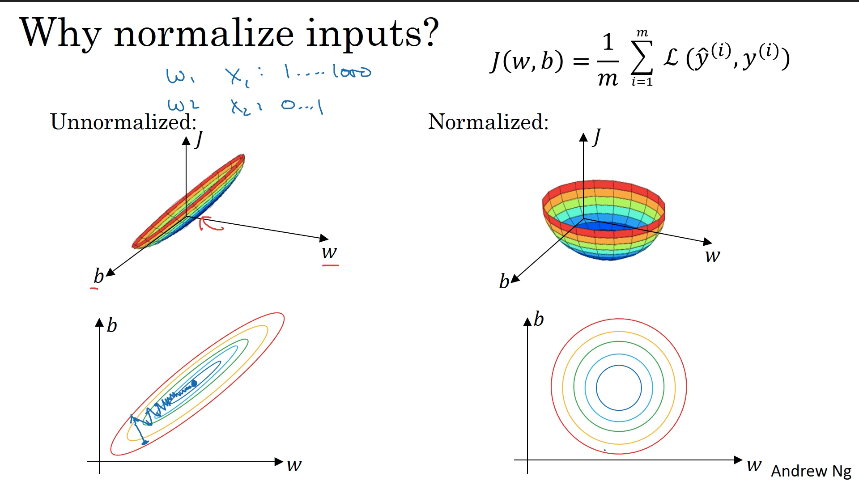
정규화 되기 전 그래프를 그려보면 가늘고 길쭉한 형태이다. x1은 1~1000의 범위를 가지고 x2는 0~1의 범위를 가진다고 한다면 이들을 제어하는 가중치 w의 범위 또한 매우 크고 다른 값을 갖게 된다. 반면 정규화를 하고 나면 동일한 범위를 가지게 되기 때문에 가중치 범위가 크게 차이 나지 않아 균형적인 그래프 형태를 띄게 된다. 여기에 경사하강법을 적용하면 unnormalized는 균형적이지 않아 시작점에 영향을 많이 받게 되고, 많은 스텝이 필요해 매우 작은 학습률을 사용하게 된다. 하지만 normalized의 경우 최솟값으로 바로바로 찾아 갈 수 있어 큰 학습률을 적용 할 수 있고 결론적으로 학습속도가 빨라지는 장점이 있다.
Standardization(표준화)
표준화는 스케일을 평균 0 분산 1 이 되도록 만든다. 이는 정규분포를 표준정규분포로 변환하는 것과 동일하다.
머신러닝에서 역할은 노멀라이즈와 같다.
하단의 그림을 보면 Normalization과 Standardization의 차이가 시각적으로 이해가 잘된다.

'머신러닝' 카테고리의 다른 글
| K means 클러스터링 (0) | 2022.06.15 |
|---|---|
| 차원축소와 PCA(주성분 분석) (0) | 2022.06.15 |
| 부스팅 모델 (1) | 2022.06.15 |
| 랜덤 포레스트 Random forest (0) | 2022.06.14 |
| 결정 트리 Decision Tree (0) | 2022.06.14 |